publications
For conference ranking, please refer to:
- Portal Ranking: The Computing Research and Education Association of Australasia.
- Top Computer Science Conferences.
- Google Scholar Metrics.
2024
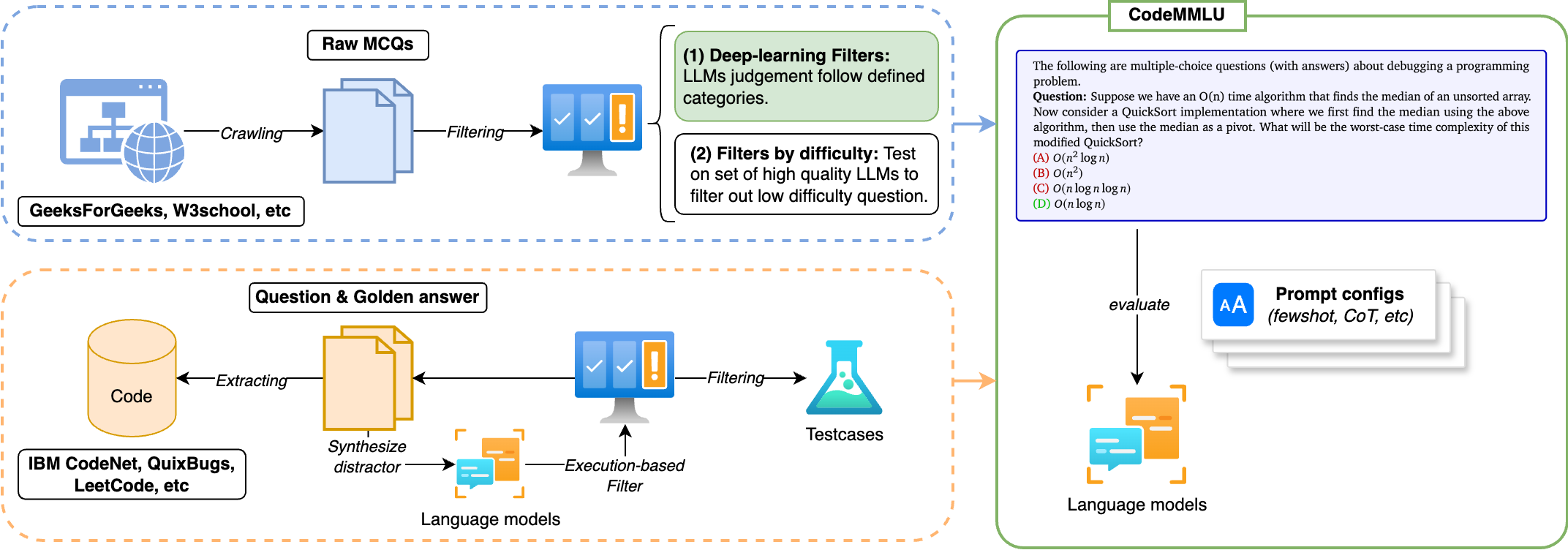
- CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMsDung Nguyen Manh, Thang Phan Chau, Nam Le Hai, Thong T. Doan, Nam V. Nguyen, Quang Pham, and Nghi D. Q. Bui2024
Recent advancements in Code Large Language Models (CodeLLMs) have predominantly focused on open-ended code generation tasks, often neglecting the critical aspect of code understanding and comprehension. To bridge this gap, we present CodeMMLU, a comprehensive multiple-choice question-answer benchmark designed to evaluate the depth of software and code understanding in LLMs. CodeMMLU includes over 10,000 questions sourced from diverse domains, encompassing tasks such as code analysis, defect detection, and software engineering principles across multiple programming languages. Unlike traditional benchmarks, CodeMMLU assesses models’ ability to reason about code rather than merely generate it, providing deeper insights into their grasp of complex software concepts and systems. Our extensive evaluation reveals that even state-of-the-art models face significant challenges with CodeMMLU, highlighting deficiencies in comprehension beyond code generation. By underscoring the crucial relationship between code understanding and effective generation, CodeMMLU serves as a vital resource for advancing AI-assisted software development, ultimately aiming to create more reliable and capable coding assistants.
@misc{manh2024codemmlumultitaskbenchmarkassessing, title = {CodeMMLU: A Multi-Task Benchmark for Assessing Code Understanding Capabilities of CodeLLMs}, author = {Manh, Dung Nguyen and Chau, Thang Phan and Hai, Nam Le and Doan, Thong T. and Nguyen, Nam V. and Pham, Quang and Bui, Nghi D. Q.}, year = {2024}, eprint = {2410.01999}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2410.01999}, } - On the Impacts of Contexts on Repository-Level Code GenerationNam Le Hai, Dung Manh Nguyen, and Nghi D. Q. Bui2024
CodeLLMs have gained widespread adoption for code generation tasks, yet their capacity to handle repository-level code generation with complex contextual dependencies remains underexplored. Our work underscores the critical importance of leveraging repository-level contexts to generate executable and functionally correct code. We present RepoExec, a novel benchmark designed to evaluate repository-level code generation, with a focus on three key aspects: executability, functional correctness through comprehensive test case generation, and accurate utilization of cross-file contexts. Our study examines a controlled scenario where developers specify essential code dependencies (contexts), challenging models to integrate them effectively. Additionally, we introduce an instruction-tuned dataset that enhances CodeLLMs’ ability to leverage dependencies, along with a new metric, Dependency Invocation Rate (DIR), to quantify context utilization. Experimental results reveal that while pretrained LLMs demonstrate superior performance in terms of correctness, instruction-tuned models excel in context utilization and debugging capabilities. RepoExec offers a comprehensive evaluation framework for assessing code functionality and alignment with developer intent, thereby advancing the development of more reliable CodeLLMs for real-world applications. The dataset and source code are available at this https URL.
@misc{hai2024impactscontextsrepositorylevelcode, title = {On the Impacts of Contexts on Repository-Level Code Generation}, author = {Hai, Nam Le and Nguyen, Dung Manh and Bui, Nghi D. Q.}, year = {2024}, eprint = {2406.11927}, archiveprefix = {arXiv}, primaryclass = {cs.SE}, url = {https://arxiv.org/abs/2406.11927}, }
2023
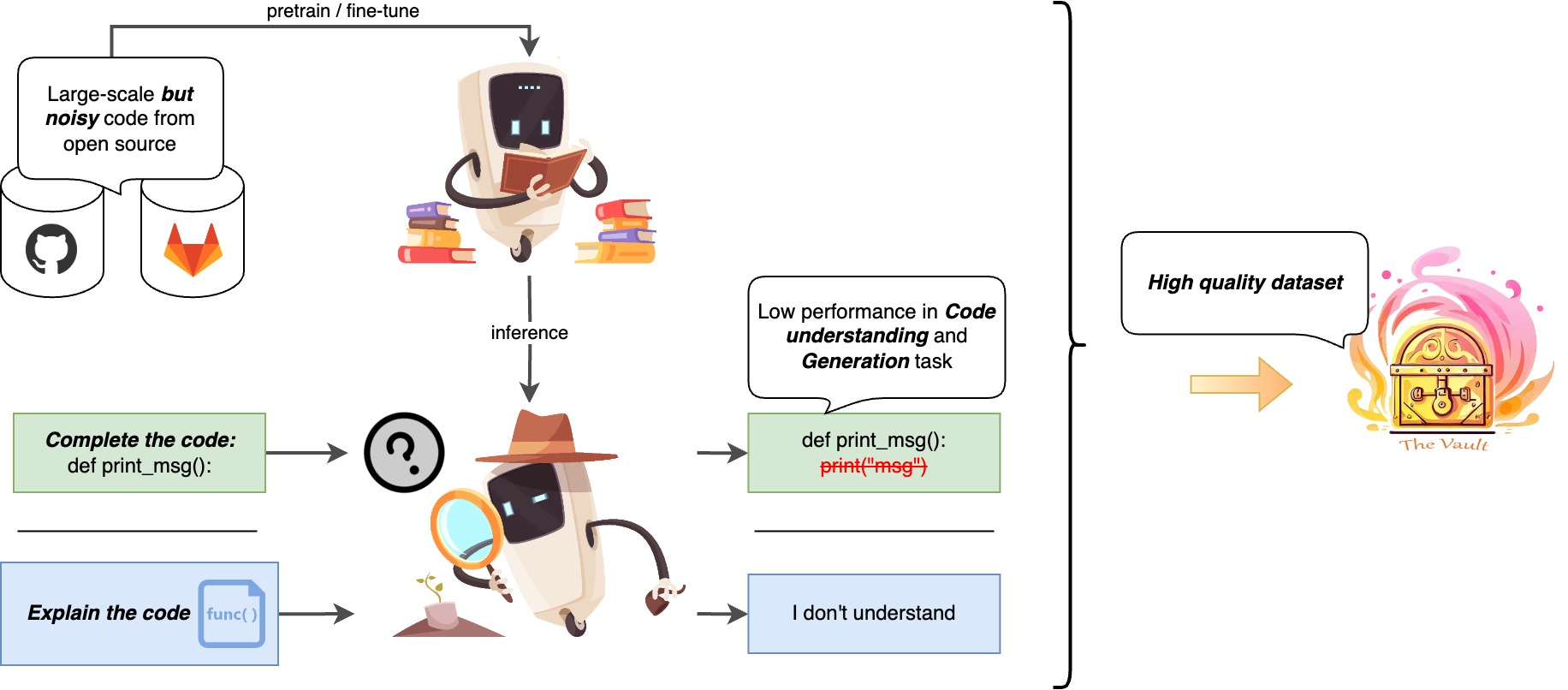
- The Vault: A Comprehensive Multilingual Dataset for Advancing Code Understanding and GenerationDung Nguyen Manh, Nam Le Hai, Anh T. V. Dau, Anh Minh Nguyen, Khanh Nghiem, Jin Guo, and Nghi D. Q. Bui2023
We present The Vault, an open-source, large-scale code-text dataset designed to enhance the training of code-focused large language models (LLMs). Existing open-source datasets for training code-based LLMs often face challenges in terms of size, quality (due to noisy signals), and format (only containing code function and text explanation pairings). The Vault overcomes these limitations by providing 40 million code-text pairs across 10 popular programming languages, thorough cleaning for 10+ prevalent issues, and various levels of code-text pairings, including class, function, and line levels. Researchers and practitioners can utilize The Vault for training diverse code-focused LLMs or incorporate the provided data cleaning methods and scripts to improve their datasets. By employing The Vault as the training dataset for code-centric LLMs, we anticipate significant advancements in code understanding and generation tasks, fostering progress in both artificial intelligence research and software development practices.
@misc{manh2023vault, title = {The Vault: A Comprehensive Multilingual Dataset for Advancing Code Understanding and Generation}, author = {Manh, Dung Nguyen and Hai, Nam Le and Dau, Anh T. V. and Nguyen, Anh Minh and Nghiem, Khanh and Guo, Jin and Bui, Nghi D. Q.}, year = {2023}, eprint = {2305.06156}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, }
2022
- ViWOZ: A Multi-Domain Task-Oriented Dialogue Systems Dataset For Low-resource LanguagePhi Nguyen Van, Tung Cao Hoang, Dung Nguyen Manh, Quan Nguyen Minh, and Long Tran Quoc2022
Most of the current task-oriented dialogue systems (ToD), despite having interesting results, are designed for a handful of languages like Chinese and English. Therefore, their performance in low-resource languages is still a significant problem due to the absence of a standard dataset and evaluation policy. To address this problem, we proposed ViWOZ, a fully-annotated Vietnamese task-oriented dialogue dataset. ViWOZ is the first multi-turn, multi-domain tasked oriented dataset in Vietnamese, a low-resource language. The dataset consists of a total of 5,000 dialogues, including 60,946 fully annotated utterances. Furthermore, we provide a comprehensive benchmark of both modular and end-to-end models in low-resource language scenarios. With those characteristics, the ViWOZ dataset enables future studies on creating a multilingual task-oriented dialogue system.
@misc{van2022viwoz, title = {ViWOZ: A Multi-Domain Task-Oriented Dialogue Systems Dataset For Low-resource Language}, author = {Van, Phi Nguyen and Hoang, Tung Cao and Manh, Dung Nguyen and Minh, Quan Nguyen and Quoc, Long Tran}, year = {2022}, eprint = {2203.07742}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, }